PostgreSQL - BRIN Index
16 Sep 2016What if I ask you about your favorite food? Well, is it Chinese Dumplings or is it a family sized Pizza with some extra cheese on it? In my case, it is BOTH! Suppose you’re in a restaurant and are provided a menu with (say) 200 items in total. No doubt that I’ll directly look into a section that says ‘Chinese’ for a Mo:Mo or the ‘Italian’ section for a Pizza because they’re apparently my favorites. So, while my other friends would be busy going through the first 20 items in the menu, I’ll be done deciding with what I’m going to have for lunch. I hope this gives some idea about what we’re about to learn now.
Now, with a heavy heart, let us forget the food thing that I was talking about. Sad it is! I mean, we are still sticking with the menu and the food but in a different way altogether. By now, you must have guessed that I’m interested in the M-E-N-U thing here. Okay, let me make the things clear. All I’m trying to know is your favorite database. Menu, database, foodstuffs, orders and queries…… does it make sense?
If you ask me what my favorite database is, I’d obviously think for a while before answering. Like some would prompt for Italian and some would for Chinese, preferences aren’t the only thing to consider while it’s about databases. Performance, context and implementation come prior to preferences here. But there’s this thing about PostgreSQL called BRIN (index) that I’m about to share as I like it a lot, at least until now. Although, I am still a beginner with PostgreSQL and there’s still a lot more in it for me to explore.
Talking about BRIN that stands for Block Range Index, it is a whole new type of index introduced in PostgreSQL 9.5. Most of us must be aware that 100 million rows in a database (or PostgreSQL in our case) are stored in various pages or blocks of certain size.
This basically means that for 100 million rows, there are 100 million btree indexes. Btree is usually the default index type in most databases. So the equation here is pretty simple i.e. n million indexes for n million rows. But No! it isn’t as simple as most of us think.
Imagine the time PostgreSQL takes to create n million indexes or even trillions and trillions of such indexes. Yes, here we’re focusing a bit into big data. Imagine a situation where you have to have a bulk scan of a million rows. That can generate a lot of performance overhead for the direct btree index scan. Trust me, at some point, it will.
Introduction of BRIN since PostgreSQL 9.5 has somehow made things a bit easier, at least for the database engine. Let us first have a look at this:
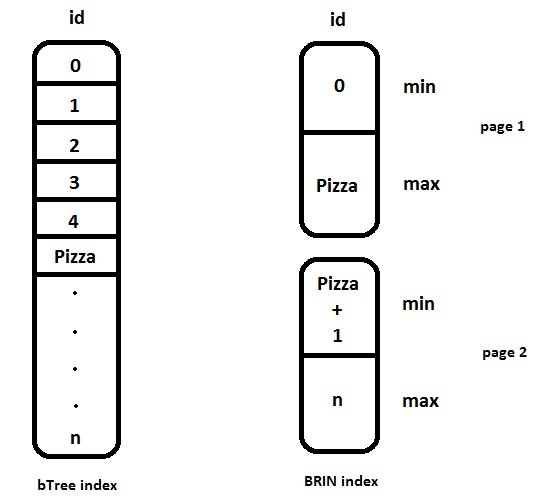
Working of Brin
So for n million rows, we now have (2 x p) number of indexes where p is the number of page blocks of the entire dataset.
Therefore, it takes a lot less time and memory to create indexes on a huge dataset however; I cannot really guarantee that this method will always be better than the btree method or even the normal sequential scan. I mean it totally depends upon the implementation and one’s skill to design the database.
What BRIN basically does is create a maximum and minimum value for the indexing column of the table (say id) for each page block. The size of the page block can also be customized accordingly which will eventually give you certain number of page blocks. Also, let me mention that BRIN comes handy when one has to extract a bulk of data rather than extracting a single row of data. So, when I have to extract data from rows having id values between say 10000000 and 20000000, the database goes through a BRIN index scan, checks on the maximum and minimum value of only those id fields that satisfy the query and returns a set of result. This removes a lot of overhead of scanning each and every row starting from row 1. If you want to some more details about the internal working of BRIN index, there are sources over the internet that you can obviously refer to. But in short, BRIN does a Bitmap Heap Scan which technically skips unwanted rows according to the bit values.
Fascinating, isn’t it? Well here are some benchmark results that I’d like to post using our favorite EXPLAIN ANALYZE.
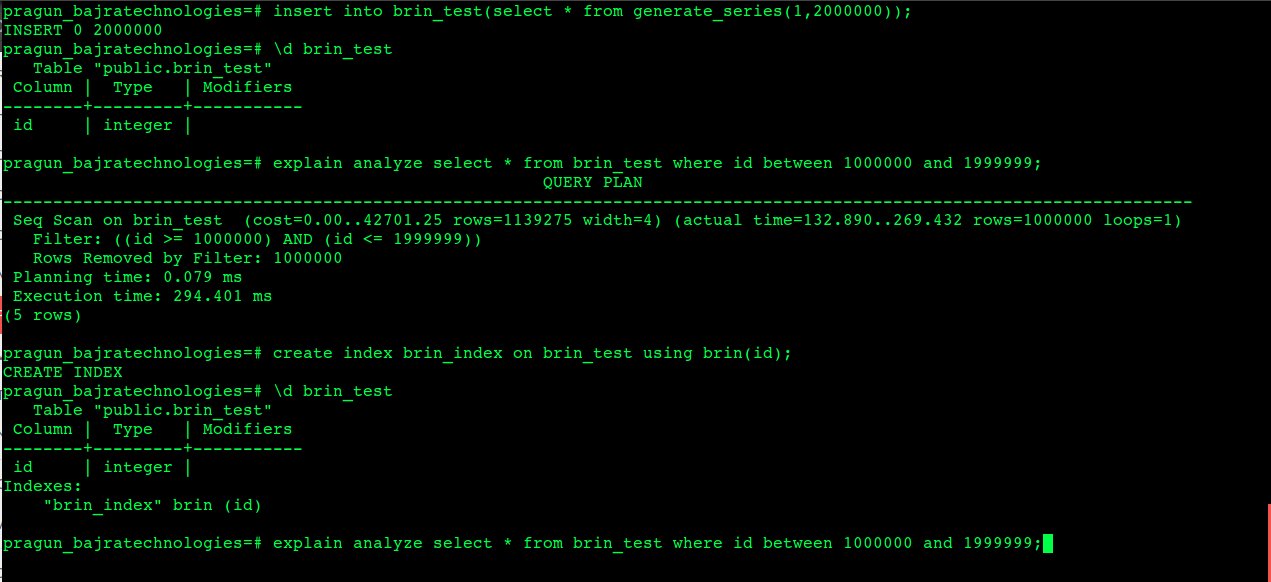
Brin Benchmark
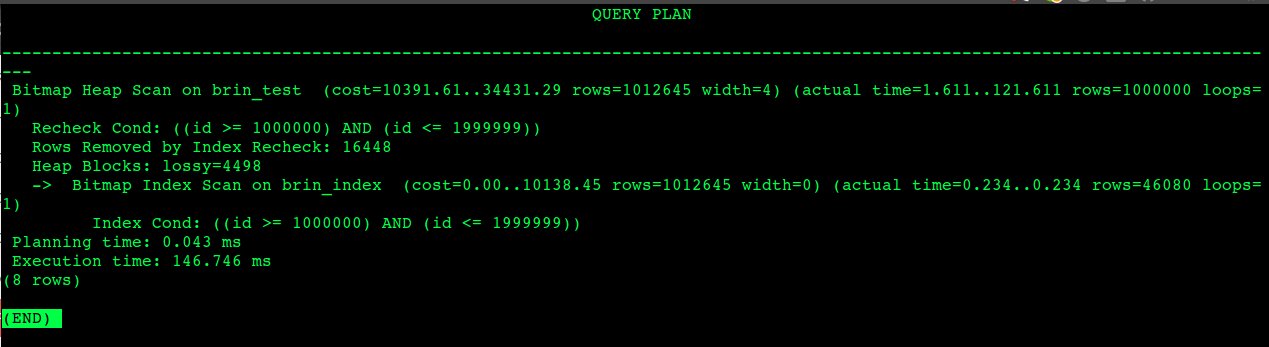
Brin Benchmark
BRIN index is a revolution in itself. I am not quite sure about other databases but to my knowledge, other databases too have something similar to BRIN but with a different name. I am looking forward to use it to optimize queries while handling big data. Eventually, I admit that BRIN cannot always be the best between all indexes but yes, it is obviously worth implementing most of the times.

